Reconnaissance: A Guide for Web App Security Testing
Reconnaissance is everything. It’s the phase where hunters identify their target’s digital footprint — subdomains, endpoints, urls, technologies, and other surface-level exposures that can lead to deeper vulnerabilities.
What you’ll learn
In this article’ I will share some simple ways to fastest our reconn to the target. This guide is to help beginners and intermediate-level security practitioners, build a field-tested methodology for the reconnaissance phase of security assessments. It focuses on techniques proven effective in identifying exposed assets, services, and potential attack vectors across dynamic environments — including production, staging, and externally-facing systems. Rather than abstract theory, the content is grounded in actionable steps applicable to both offensive engagements and vulnerability research.
What you’ll need
Well’ your prepared operating system, either Windows, Linux or Mac. As long as you have the prerequisites – Python (better if you have both Python3 and Python2), Go, NodeJS, Git, and npm, installed on your machine.
List of tools/cli that we need for your reconn.
Or you can go to this link KingOfBugBountyTips
| Tools |
Cli |
| Shodan |
anew |
| IntelX |
amass |
| Censys |
subfinder |
| crt.sh |
assetfinder |
| FoFa |
dnsx |
| Zap Proxy |
massdns |
| SecurityTrails |
puredns |
| URLScan |
httpx |
|
naabu |
|
hakrawler |
|
waybackurls |
|
gau |
|
nuclei |
|
Short Name Scanner (IIS) |
|
anew |
|
qsreplace |
|
chaos |
|
notify |
|
ffuf |
|
gowitness |
|
gobuster |
|
dirbuster |
|
LinkFinder |
|
SecretFinder |
|
uro |
|
Arjun |
|
Corsy |
|
Param |
|
gf |
|
httprobe |
|
gf pattern |
|
feroxbuster |
|
urldedupe |
|
DorkEye |
|
S3BucketMisconf |
|
java2s3 |
I won’t be discussing all CLI and tools in this topic’ only the ones I frequently use during my reconn phase. However, it’s much better if you install all the tools mentioned.
The Reconn Phase
We will start our recon phase using Shodan.
is a search engine that scans and indexes internet-connected devices — from web servers, APIs, industrial control systems, and webcams to IoT devices. Unlike Google, which indexes content, Shodan indexes services, ports, banners, and device metadata.
This makes it incredibly useful in the recon phase, especially when you want to:
Identify exposed services and ports
Discover forgotten or shadow assets
Detect misconfigured devices or applications
Monitor internet-facing infrastructure
🧪 Practical Use Cases
| Use Case |
Example |
| Find exposed Web Server |
title:"Tomcat" |
| Discover staging environments |
hostname:"staging.target.com" |
| Check expired/self-signed SSL |
ssl.cert.expired:true |
| Identify old tech stacks |
product:"Apache" version:"2.2" |
| Map org-wide IPs |
org:"Target Inc" or ASN lookup |
| Passive port scan |
hostname:"api.target.com" |
| IoT leakage |
product:"webcamxp" or title:"Camera" |
| 🔐 OffSec Tip
Shodan queries are passive — they don’t touch the target. Ideal for stealth recon or
checking scope boundaries. However, some results may be outdated, so verify findings before exploitation.
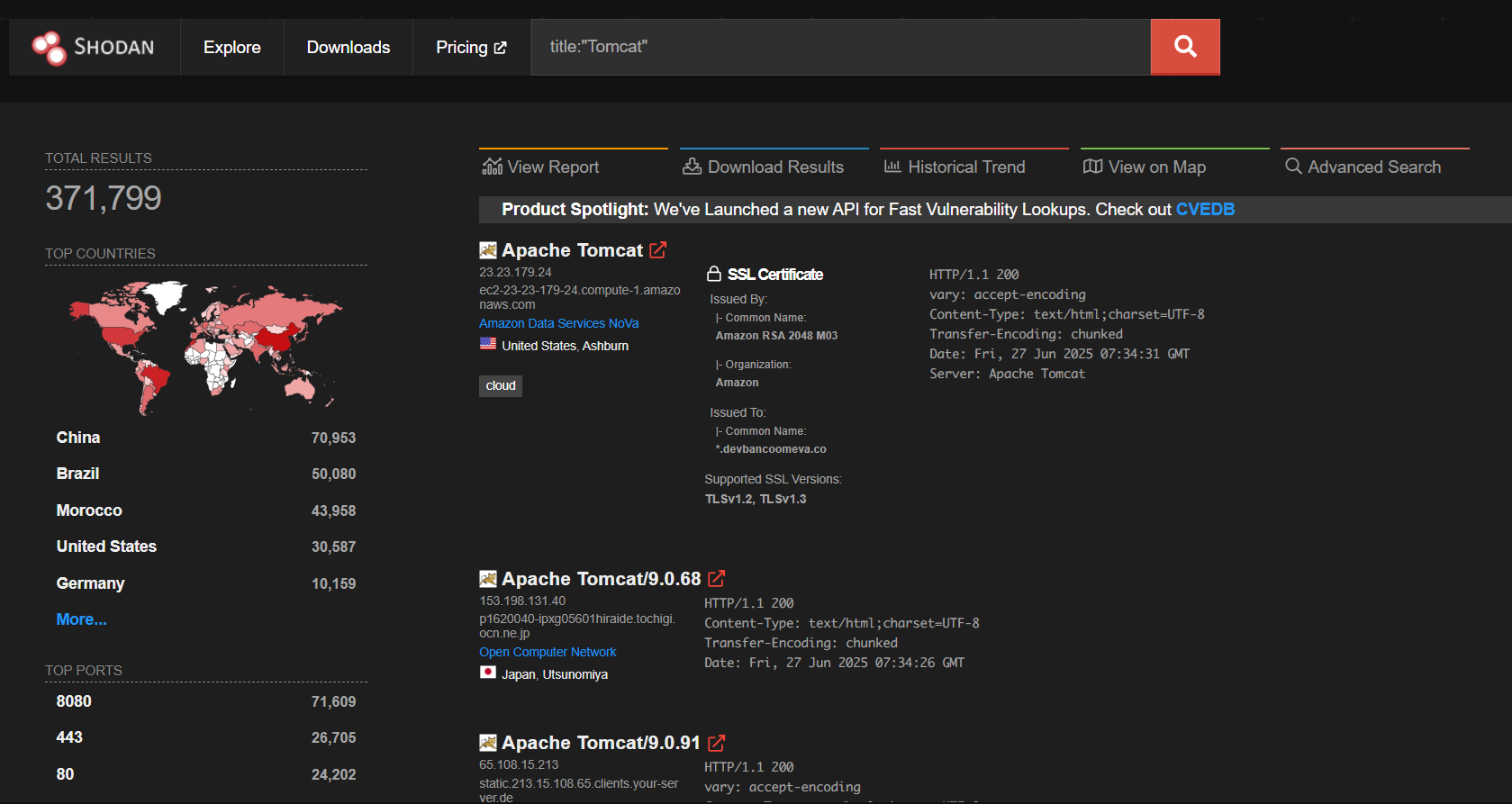
You can also search for exposed CCTV:
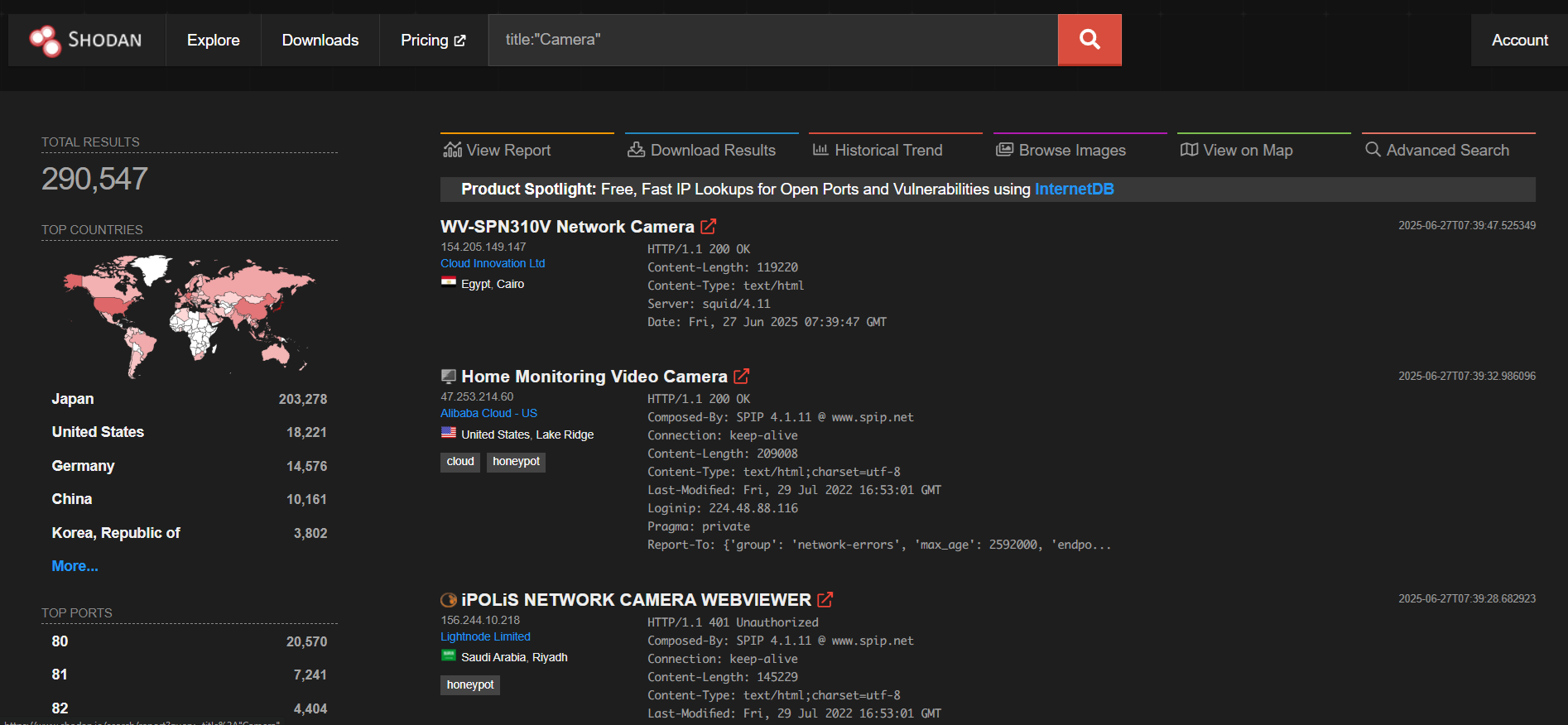
browse on image tab and you’ll some footage:
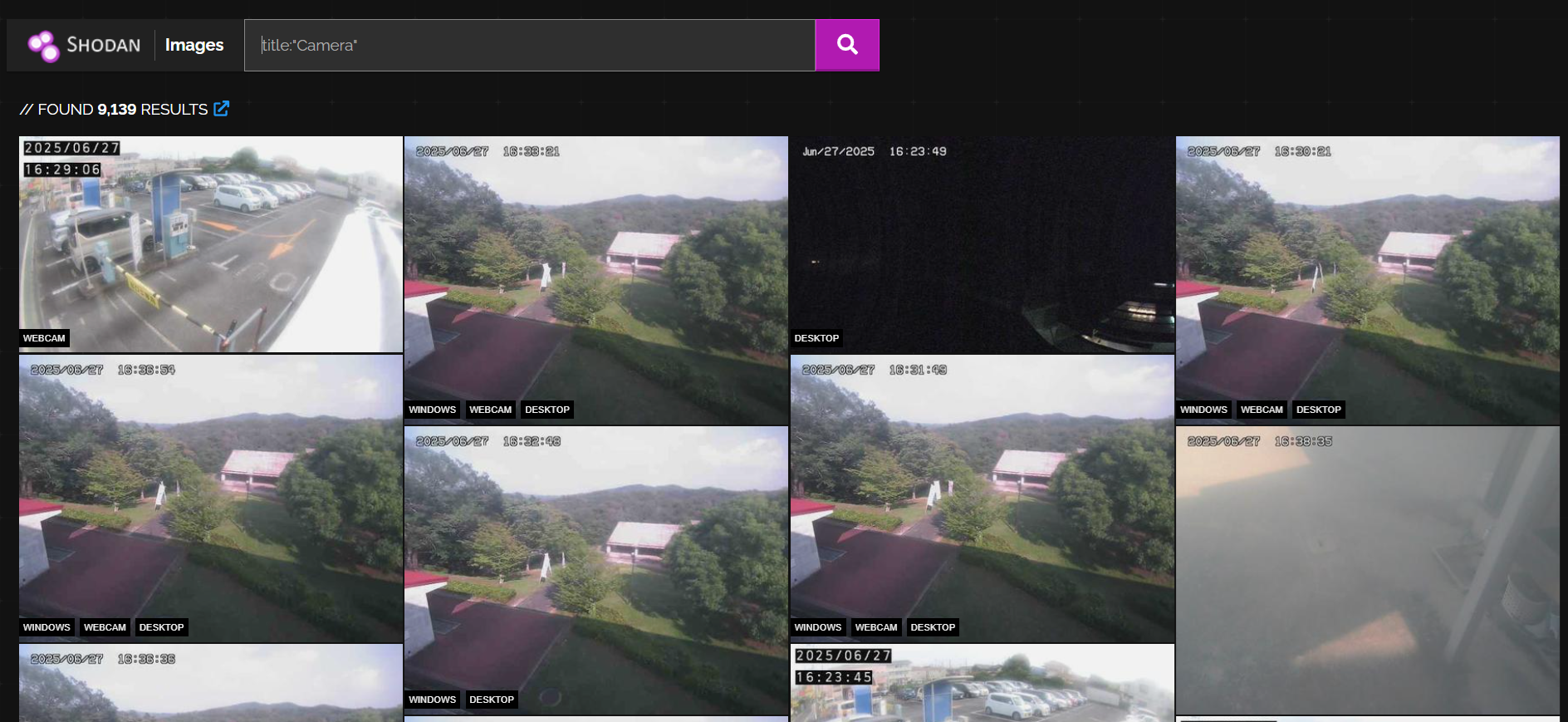
Alternatively we can use shodan cli. Right on your terminal:
pip install -U --user shodan
|
Once installed shodan cli, you need to setup your API token. You can find your own API token on their website just create an account:
shodan init <YOUR_API_KEY>
|
Command Overview
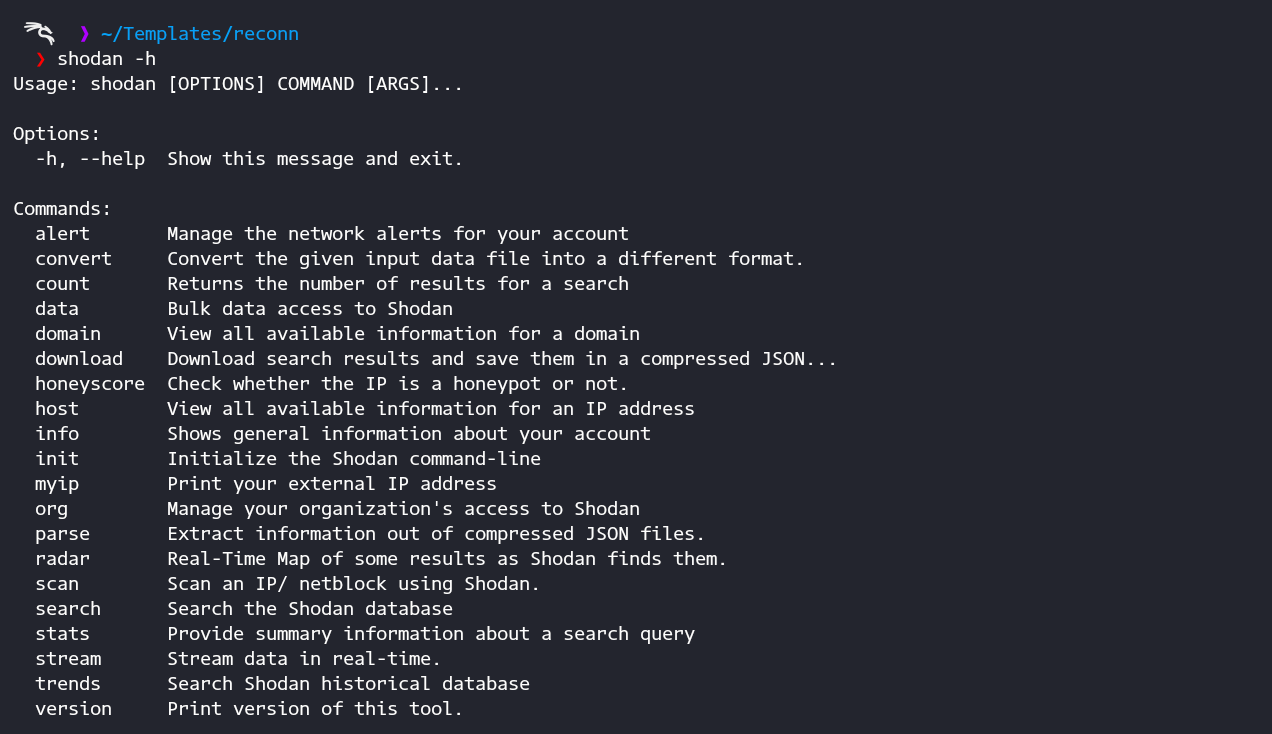
Searching for your Target
-> For example we will targeting Yandex. On your terminal run:
shodan host 158.160.167.21
|
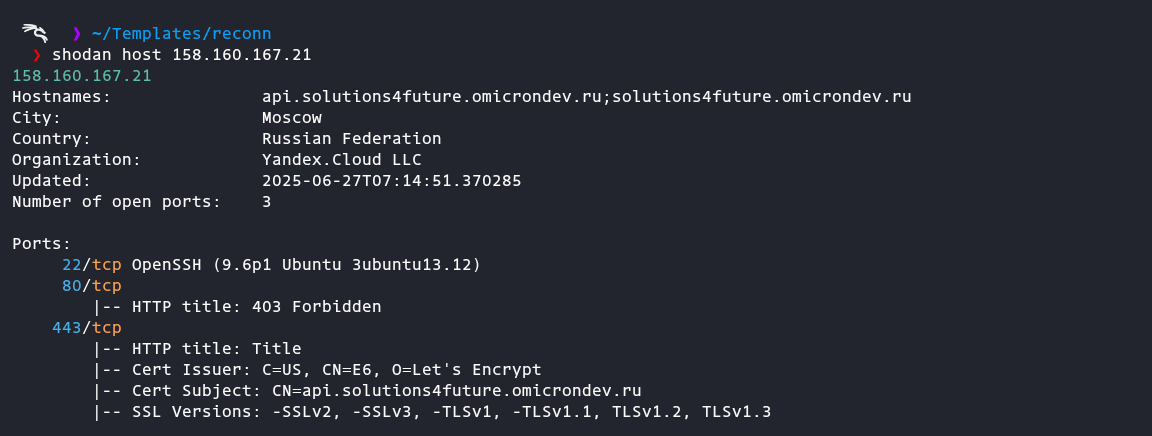
Search for Login page
shodan search 'http.title:"Login" yandex.com'
|
then you will get another IP own by Yandex
51.250.98.174 443 preprod.scontrol.silky-hands.ru HTTP/1.1 200 OK\r\nServer: nginx\r\nDate: Thu, 26 Jun 2025 04:43:28 GMT\r\nContent-Type: text/html; charset=UTF-8\r\nTransfer-Encoding: chunked\r\nConnection: keep-alive\r\nVary: Accept-Encoding\r\nSet-Cookie: _csrf-backend=2edd1a0e95da31a4abe1873eb6836eb2b1663bdb504721556afce62bce840643a%3A2%3A%7Bi%3A0%3Bs%3A13%3A%22_csrf-backend%22%3Bi%3A1%3Bs%3A32%3A%22irnO7jqsIFpBZD0Ji9--Ft86kzBg2gyN%22%3B%7D; path=/; HttpOnly; SameSite=Lax\r\nAlt-Svc: h3=":443"; ma=86400\r\nX-XSS-Protection: 1; mode=block\r\nX-Content-Type-Options: nosniff\r\nReferrer-Policy: no-referrer-when-downgrade\r\nContent-Security-Policy: default-src 'self' https: wss: data: blob: 'unsafe-inline' 'unsafe-eval'; frame-ancestors 'self' http://webvisor.com http://*.webvisor.com https://*.yandex.ru https://*.yandex.com;\r\nPermissions-Policy: interest-cohort=()\r\nStrict-Transport-Security: max-age=63072000; includeSubDomains; preload\r\nX-Frame-Options: SAMEORIGIN\r\n\r\n
|
Now we will move to FoFa
| FOFA is another powerful recon tool — often compared to Shodan
(Fingerprint of All) is a cyber asset search engine, similar to Shodan and Censys, used for finding internet-facing systems and identifying their technologies.

Let’s try the basic FoFa search syntax:
app="Tomcat" && country="PH"
|

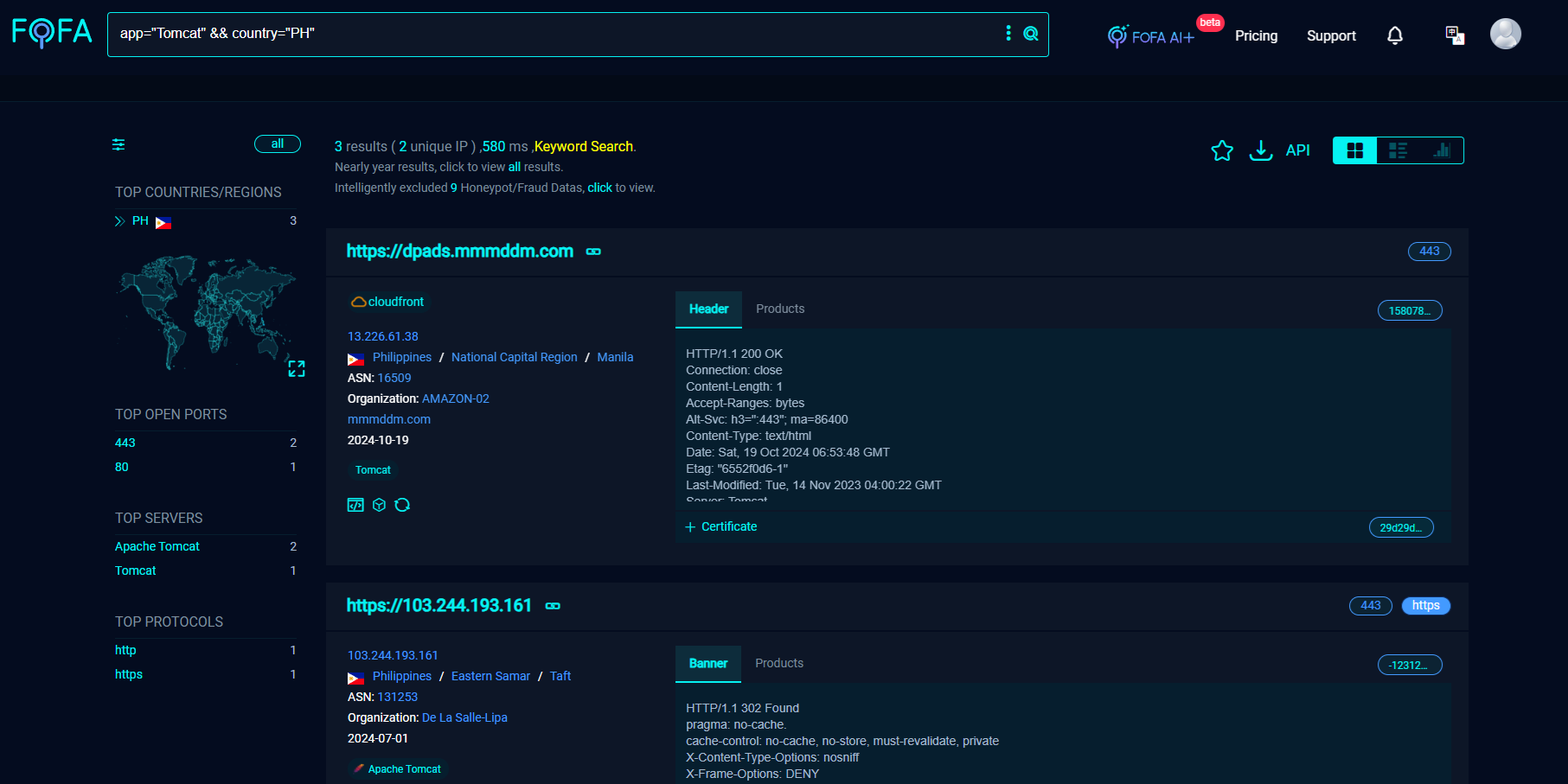
Other some basic query examples:
By Domain:
Searching for Login:
Searching for used backend:
header="X-Powered-By: PHP"
|
Searching for Title:
Searching for Sub-domains:
Searching for Web App:
app="ThinkPHP" && country="PH"
|
Next, let’s play with URLs:
Lets go from basics. The inurl operator helps refine Google searches by filtering results that contain specific words or patterns within the URL. With the power of Google dorks for reconn phase, this is useful for finding.
Example, let’s say:
inurl: "/admin/dashboard" site:gov.ph
|
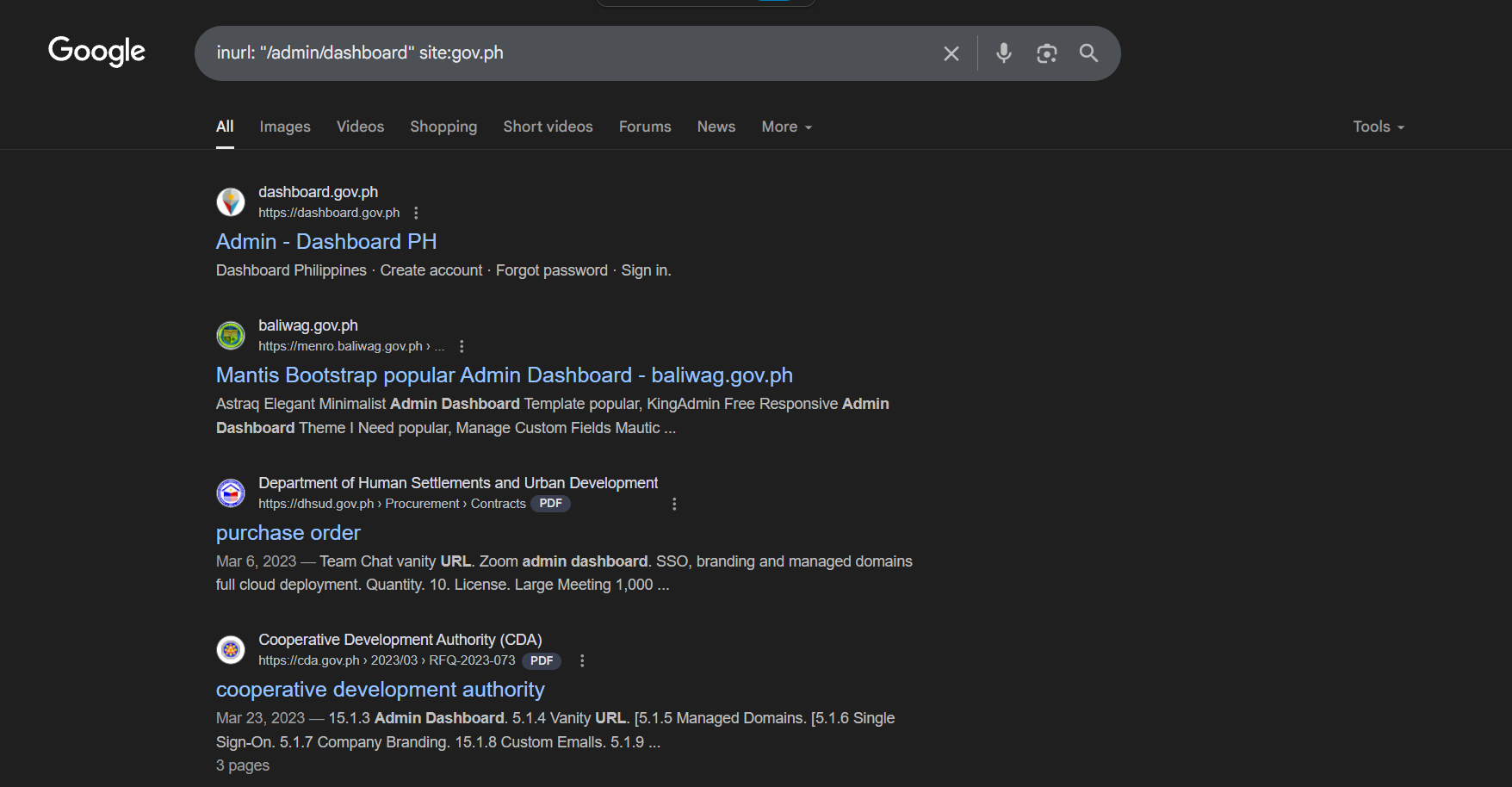
Results will not only give with dashboard title, sometimes it gives some sensitive info like this:
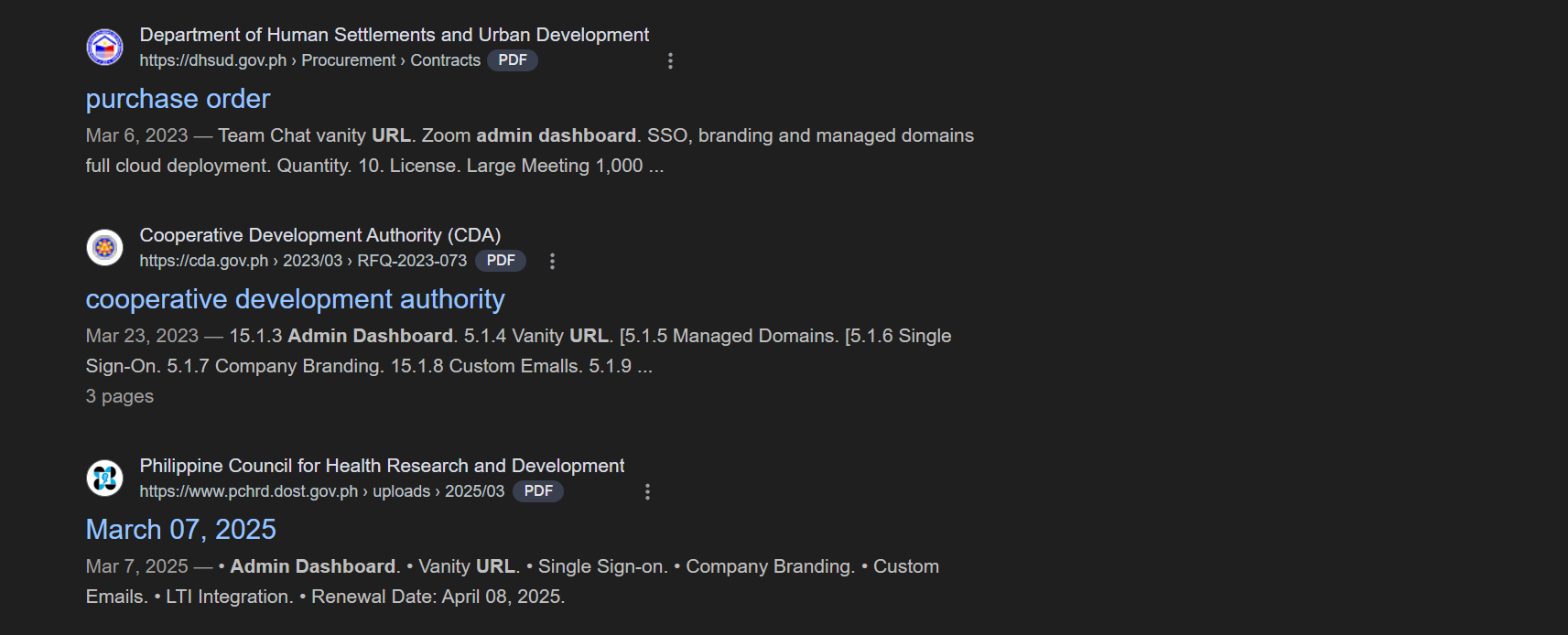
By analyzing commonly used paths across websites, we gain initial insight into potential entry points. However, for greater depth and precision, combining multiple dorks allows for more effective enumeration. Shifting our focus toward sensitive or context-specific paths—especially within web applications and APIs can significantly increase the likelihood of uncovering hidden endpoints or exposed files that may contain critical, overlooked information.
URLScan
Playing with URLs we will use urlscan.io. A powerful tool for recon, OSINT, and threat hunting. It lets you search and explore historical scans of URLs, subdomains, IPs, and even JavaScript files.
Basic query in URLScan
🔹 By Domain or Subdomain:
🔹 By Hostname (e.g., subdomain):
page.domain:sub.target.com
|
🔹 By URL Contents (Path, Query, etc):
page.url:"/admin"
page.url:"api_key"
|
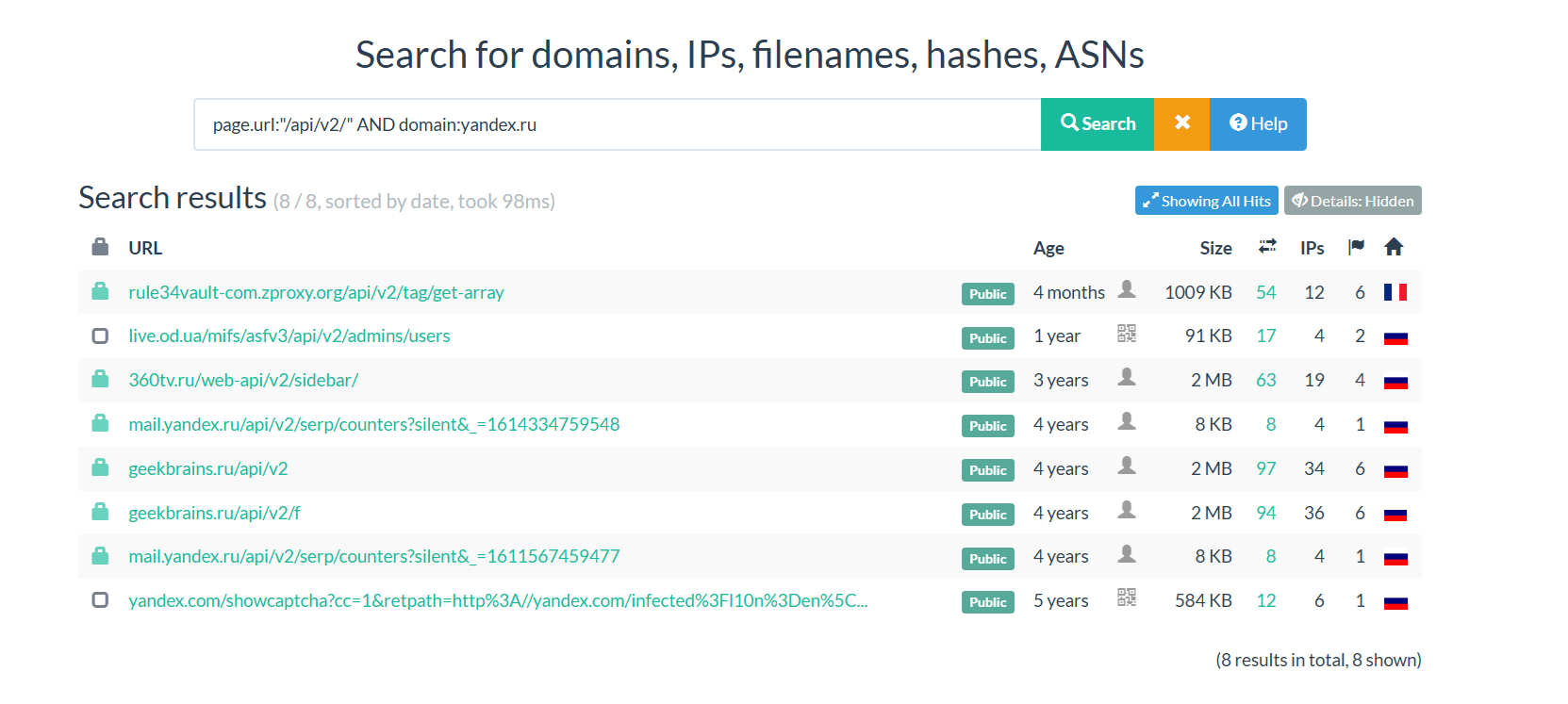
In this example, I search for API’s of yandex
query:
page.url:"/api/v2/" AND domain:yandex.ru
|
Censys
| A search engine for internet-facing infrastructure, similar to Shodan and FOFA, but with a stronger focus on TLS certificates, banners, and enterprise asset mapping.
Censys have WebUI and Cli for users. It depends on you—use whichever you’re more comfortable with.
🛠️ Censys Web UI: Basic Search Examples:
🔹 Search by Domain (including subdomains)
services.tls.certificates.leaf_data.subject.common_name: "*.target.com"
|
Or:
parsed.names: "api.target.com"
|
🔹 Find All Certs Issued to Domain
parsed.subject.common_name: "target.com"
|
🔹 Find IPs Hosting Domain
services.http.response.body: "target.com"
|
Or:
services.tls.certificates.leaf_data.subject.common_name: "target.com"
|
🔹 Filter by Technology
services.http.response.html_title: "Login"
services.banner: "Apache"
services.service_name: "https"
|
💻 Python: Using Censys CLI for Recon
You can install Censys cli by running:
Now you have to authenticate with your account:
| Enter your API ID and API Secret from https://search.censys.io/account/api
🔍 Censys CLI Usage
For basic host search:
censys search 'services.tls.certificates.leaf_data.subject.common_name: "*.target.com"' --index hosts
|
| Finds IPs with SSL certs matching *.target.com
Extract Subdomains from Certs
censys search 'parsed.names: "target.com"' --index certificates --fields parsed.names
|
| Use this to collect wildcard subdomains and legacy cert names.
Find Login Pages
censys search 'services.http.response.html_title: "Login"' --index hosts --fields ip, services.port, services.http.response.html_title
|
Check for Open Redis
censys search 'services.service_name: "redis"' --index hosts --fields ip, services.port
|
Looking for Jenkins Dashboards ?
censys search 'services.http.response.html_title: "Dashboard [Jenkins]"' --index hosts
|
Combining CLI Tools for Deep Recon and Content Discovery
Once you’ve mapped your target domains and subdomains, the next phase is to actively extract hidden paths, parameters, endpoints, and secrets. This is where chaining multiple recon tools becomes essential. Instead of relying on a single source, we merge the power of tools like waybackurls, gau, katana, feroxbuster, linkfinder, gf, and more — allowing us to build a richer and more actionable attack surface.
| 🧠 The goal is not just enumeration, but triaging attack surface for real-world impact.
- Collect archived and historical URLs
- JavaScript-aware crawler that discovers dynamic paths
- Directory brute-forcing
- Filter alive hosts and probe HTTP metadata
- Extract JS endpoints
- Find hardcoded secrets in JS files
- Filter interesting parameters for fuzzing
- Clean and mutate URLs for testing
🚀 Sample Recon Workflow
🔄 Combine and Clean URLs from Passive Sources
cat subdomains.txt | waybackurls > wayback.txt
cat subdomains.txt | gau >> wayback.txt
cat wayback.txt | sort -u | uro > clean_urls.txt
|
✅ Probe for Live Endpoints
cat clean_urls.txt | httpx -silent -status-code -tech-detect -title > live_urls.txt
|
🧪 Extract JavaScript Endpoints
cat live_urls.txt | grep '\.js' | httpx -silent > js_links.txt
cat js_links.txt | xargs -n1 -P10 -I{} python3 linkfinder.py -i {} -o cli >> js_endpoints.txt
|
🔐 Scan JS for Secrets
cat js_links.txt | xargs -n1 -P10 -I{} python3 SecretFinder.py -i {} -o cli >> secrets.txt
|
🧩 Parameter Extraction + Filtering
cat clean_urls.txt | grep '=' | gf xss >> xss.txt
cat clean_urls.txt | grep '=' | gf sqli >> sqli.txt
cat clean_urls.txt | grep '=' | gf redirect >> redirect.txt
|
🕷️ Crawling with Katana
katana -list subdomains.txt -jc -kf all -o katana.txt
|
🌪️ Directory Bruteforcing
ffuf -w wordlist.txt -u https://target.com/FUZZ -t 50 -mc 200,204,403
|
feroxbuster -u https://target.com -w wordlist.txt -t 30 -o ferox.txt
|
🗺️ Domain Enumeration
subfinder -d target.com > subs.txt
assetfinder target.com >> subs.txt
amass enum -passive -d target.com >> subs.txt
amass enum -active -d 'redacted.com' -o amass_scan
grep -i 'cname' amass_scan | cut -d ‘ ‘ -f1 | anew subdomains.txt
subfinder -d 'redacted.com' -all -recursive | anew subdomains.txt
cat subdomains.txt | httpx-pd -o subdomains_alive.txt
|
🔥 Filter hosts in a target
cat subs.txt | httpx -silent -title -tech-detect -status-code > live.txt
|
🧾 Screenshot to save time
gowitness scan file -f subdomains_alive.txt --write-db
gowitness report server
|
🗃️ Wayback + Gau + Uro + Httpx + GF
cat live.txt | waybackurls > wb.txt
cat live.txt | gau >> wb.txt
cat wb.txt | uro > urls.txt
cat urls.txt | httpx -silent -mc 200,403 -t 50 > live.txt
cat live.txt | grep "=" | tee params.txt
cat params.txt | gf xss > xss.txt
cat params.txt | gf sqli > sqli.txt
cat params.txt | gf ssrf > ssrf.txt
|
🔍 Find APIs + JS Endpoints from Archived URLs
cat urls.txt | grep -Ei "/api/|/v1/|/v2/|/graphql|/admin|/internal" > apis.txt
cat urls.txt | grep "\.js$" | sort -u > js_files.txt
cat js_files.txt | while read url; do
python3 linkfinder.py -i "$url" -o cli
done | tee js_endpoints.txt
|
🔐 JS Secrets & Auth Token Discovery
cat js_files.txt | while read url; do
python3 SecretFinder.py -i "$url" -o cli
done | tee secrets.txt
|
cat urls.txt | cut -d "/" -f 1-5 | sort -u > dirs.txt
cat dirs.txt | while read url; do
ffuf -u "$url/FUZZ" -w ~/wordlists/raft-medium-directories.txt -mc 200,403 -t 40 -o "ffuf_${url//[^a-zA-Z0-9]/_}.json"
done
|
⚙️ 5. Custom Param Discovery + Fuzzing
python3 paramspider.py -d target.com -o params/
cat params/target.com.txt >> params.txt
cat params.txt | qsreplace "FUZZ" | sort -u > fuzzable.txt
ffuf -u "https://target.com/FUZZ" -w fuzzable.txt -t 40 -mc 200,403
feroxbuster -A -u redacted_sub.com -o ferox_scan
katana -u redacted_sub.com -xhr -kf -ps -d 5 -hl -sb -o katana_scan
|
katana -list subdomains.txt -jc -kf all -o katana_raw.txt
cat katana_raw.txt | grep "\.js" | httpx -silent > katana_js.txt
cat katana_js.txt | while read js; do
python3 linkfinder.py -i "$js" -o cli
done | tee katana_endpoints.txt
|
⚡ 7. Live Hosts + Favicon Hashing (Asset Fingerprinting)
cat subdomains.txt | httpx -favicon -silent > favicons.txt
|
🔐 Hunt for API Keys
subfinder -d target.com -silent > subs.txt
httpx -l subs.txt -mc 200 -silent > live_subs.txt
gau -subs target.com | grep ".js" | tee js_files.txt
cat js_files.txt | while read url; do curl -s $url >> all_javascript_dump.txt; done
grep -iE "apikey|token|secret|authorization|bearer" all_javascript_dump.txt
const stripeSecretKey = "sk_live_51N0....";
const firebaseApiKey = "AIzaSyD8a....";
Authorization: Bearer eyJhbGciOi...
regex
grep -oP '(?<=//).+' all_javascript_dump.txt
ffuf -w common.txt -u https://target.com/assets/js/FUZZ
|
Wait are we done ? Let’s go into more complex
📍 Automating Google Dorking with DorkEye
| DorkEye automates Google dorking making reconnaissance faster by quickly extracting multiple AWS URLs for analysis.
GitHub - BullsEye0/dorks-eye: Dorks Eye Google Hacking Dork Scraping and Searching Script. Dorks Eye is a script I made in python 3. With this tool, you can easily find Google Dorks. Dork Eye collects potentially vulnerable web pages and applications on the Internet or other awesome info that is picked up by Google's search bots. Author: Jolanda de Koff
Dorks Eye Google Hacking Dork Scraping and Searching Script. Dorks Eye is a scri...
For example:
Google Dorking for AWS S3 Buckets
Google dorking helps uncover exposed S3 buckets. you can use the following dork to find open s3 buckets:
site:s3.amazonaws.com "target.com"
site:*.s3.amazonaws.com "target.com"
site:s3-external-1.amazonaws.com "target.com"
site:s3.dualstack.us-east-1.amazonaws.com "target.com"
site:amazonaws.com inurl:s3.amazonaws.com
site:s3.amazonaws.com intitle:"index of"
site:s3.amazonaws.com inurl:".s3.amazonaws.com/"
site:s3.amazonaws.com intitle:"index of" "bucket"
(site:*.s3.amazonaws.com OR site:*.s3-external-1.amazonaws.com OR site:*.s3.dualstack.us-east-1.amazonaws.com OR site:*.s3.ap-south-1.amazonaws.com) "target.com"
|
☁️ Using S3Misconfig for Fast Bucket Enumeration
| S3Misconfig scans a list of URLs for open S3 buckets with listing enabled and saves the results in a user friendly HTML format for easy review.
GitHub - Atharv834/S3BucketMisconf
Contribute to Atharv834/S3BucketMisconf development by creating an account ...
📦 Finding S3 Buckets with HTTPX and Nuclei
| You can use the HTTPX command along with the Nuclei tool to quickly identify all S3 buckets across subdomains saving you significant time in recon.
subfinder -d target.com -all -silent | httpx-toolkit -sc -title -td | grep "Amazon S3"
subfinder -d target.com -all -silent | nuclei -t /home/coffinxp/.local/nuclei-templates/http/technologies/s3-detect.yaml
|
| Next we’ll use the Katana tool to download JavaScript files from target subdomains and extract S3 URLs using the following grep command:
katana -u https://site.com/ -d 5 -jc | grep '\.js$' | tee alljs.txt
cat alljs.txt | xargs -I {} curl -s {} | grep -oE 'http[s]?://[^"]*\.s3\.amazonaws\.com[^" ]*' | sort -u
|
| Alternatively you can use this powerful approach to extract all S3 URLs from JavaScript files of subdomains. First combine subfinder and HTTPX to generate the final list of subdomains then run the java2s3 tool for extraction.
subfinder -d target.com -all -silent | httpx-toolkit -o file.txt
cat file.txt | grep -oP '(?<=https?:\/\/).*' >input.txt
python java2s3.py input.txt target.com output.txt
cat output3.txt | grep -E "S3 Buckets: \['[^]]+"
cat output.txt | grep -oP 'https?://[a-zA-Z0-9.-]*s3(\.dualstack)?\.ap-[a-z0-9-]+\.amazonaws\.com/[^\s"<>]+' | sort -u
cat output3.txt | grep -oP '([a-zA-Z0-9.-]+\.s3(\.dualstack)?\.[a-z0-9-]+\.amazonaws\.com)' | sort -u
|
GitHub - mexploit30/java2s3
Contribute to mexploit30/java2s3 development by creating an account on GitH...
🗂️ Web Archive Enumeration
| Retrieving Archived URLs via the CDX API
A highly effective approach for passive URL enumeration is leveraging the CDX API from the Wayback Machine. This API allows you to extract a full list of historical URLs tied to a domain and its subdomains — often revealing endpoints no longer publicly accessible. Here’s a sample command to query it:
https://web.archive.org/cdx/search/cdx?url=*.yourtarget.com/*&collapse=urlkey&output=text&fl=original
|
For example: I use DJI as my target:
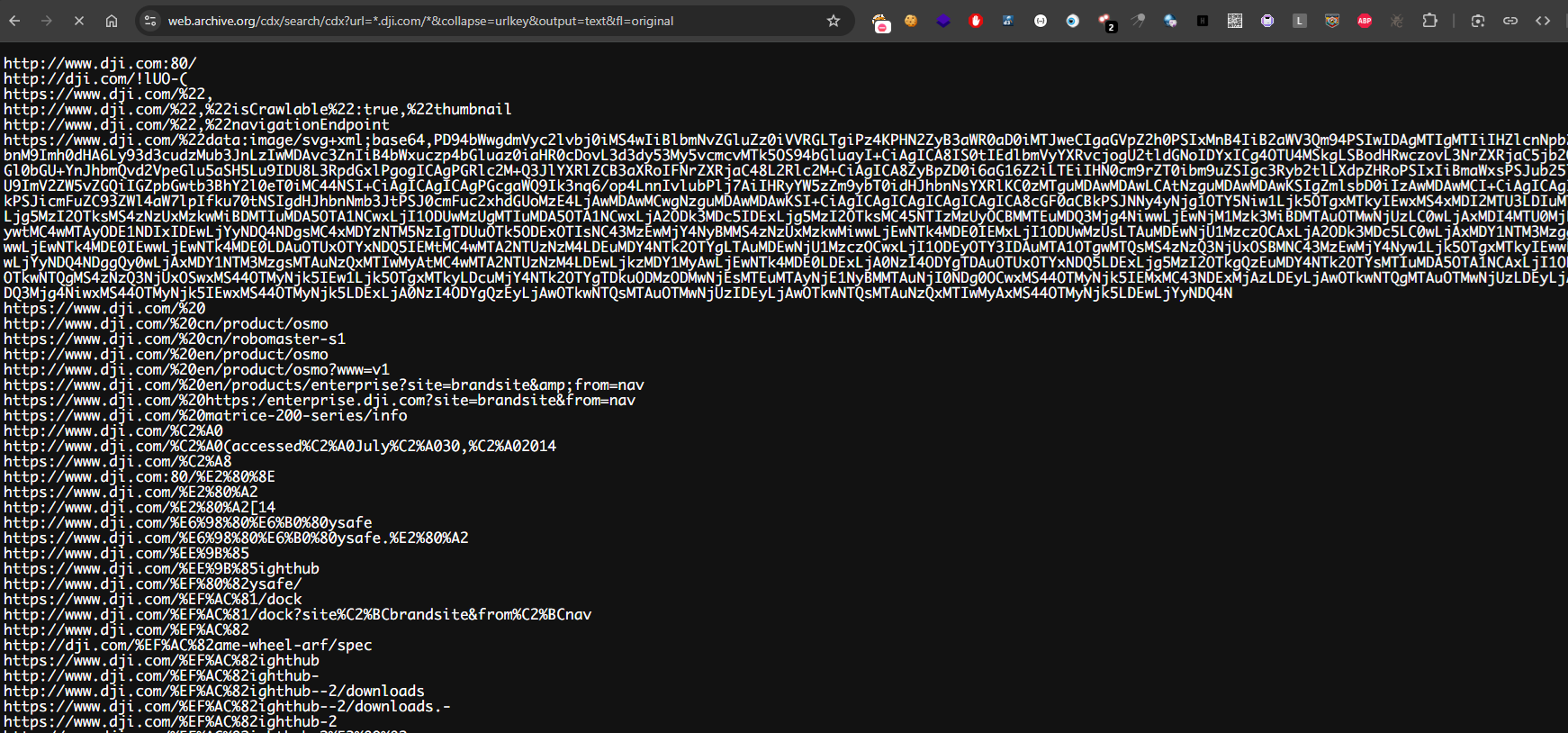
📥 Efficient Data Retrieval with cURL
When working with large datasets from the Wayback Machine, browser-based access can be slow or unstable. A more reliable method is to use curl, which enables rapid, scriptable downloading of archive data. Below is a sample command to fetch results efficiently:
curl 'https://web.archive.org/cdx/search/cdx?url=*.dji.com/*&output=text&fl=original&collapse=urlkey' > output.txt
|
After executing the command, all discovered URLs will be saved to output.txt. You can then use grep or similar tools to filter for email addresses, password patterns, or files with specific extensions.
For example, to identify potentially sensitive files, you can search for URLs ending in juicy extensions such as .env, .bak, .sql, .log, or .json — which often contain credentials, configuration data, or internal information.
cat out.txt | uro | grep -E '\.xls|\.xml|\.xlsx|\.json|\.pdf|\.sql|\.doc|\.docx|\.pptx|\.txt|\.zip|\.tar\.gz|\.tgz|\.bak|\.7z|\.rar|\.log|\.cache|\.secret|\.db|\.backup|\.yml|\.gz|\.config|\.csv|\.yaml|\.md|\.md5|\.exe|\.dll|\.bin|\.ini|\.bat|\.sh|\.tar|\.deb|\.git|\.env|\.rpm|\.iso|\.img|\.apk|\.msi|\.dmg|\.tmp|\.crt|\.pem|\.key|\.pub|\.asc'
|
📦 JavaScript File Collection Using LazyEgg
| Manually identifying and reviewing JavaScript files across a website can be time-consuming. To streamline this, you can use the LazyEgg browser extension — a tool designed to automatically extract .js file URLs from any page you visit.
| Installation:
- Install LazyEgg from the Chrome Web Store.
- Navigate to the target website and refresh the page.
- Click the
LazyEgg extension — it will automatically list all JavaScript file URLs loaded by the page.
- Copy the extracted URLs and paste them into a multi-URL opener extension to open all JS endpoints at once.
- With all scripts loaded, use your browser’s Ctrl+F / Cmd+F to search for sensitive keywords such as:
api, token, password, secret, key, jwt.
| These keywords can help reveal hardcoded credentials, API endpoints, or security misconfigurations that may be valuable during your assessment.
🚀 Active Crawling with Katana
| katana is a fast and flexible web crawler that can automatically discover active endpoints and JavaScript files from a target domain.
You can use it to enumerate all .js files for further analysis:
katana -u https://target.com -js -kf all -silent -o js_links.txt
katana -u samsung.com -d 5 -jc | grep '\.js$' | tee alljs.txt
|
js enables JavaScript file extraction.
kf all enables all known input collectors.
silent disables extra output for cleaner results.
The output file js_links.txt will contain all discovered JavaScript URLs.
🐌 Passive Crawling with GAU
echo www.samsung.com | gau | grep '\.js$' | anew alljs.txt
|
🐛 Refining Results with HTTPX
cat alljs.txt | httpx-toolkit -mc 200 -o samsung.txt
|
| With a refined list of JavaScript endpoints, the next step is to extract all hidden links and sensitive information.
GitHub - byt3hx/jsleak: jsleak is a tool to find secret , paths or links in the source code during the recon.
jsleak is a tool to find secret , paths or links in the source code during the r...
jsleaks: A tool used for analyzing JavaScript files to detect potential sensitive information or leaks.
cat samsung.txt | jsleaks -s -l -k
|
🌐 Reconn with Nuclei and look for possible vulnerabilities
nuclei -u https://yourtarget.com -tags cve, rce, lfi, xss, network, logs, config, ssrf
nuclei -l target.txt -tags cve,rce,lfi,xss,network,logs,config,ssrf -t cves/,misconfiguration/,exposures/,default-logins/,exposed-panels/,technologies/,takeovers/nuclei -u https://sample.com -tags cve, rce, lfi, xss, network, logs, config, ssrf
|
💎 Another Subdomain Enumeration but with Custom Wordlists
| Find subdomains others miss by brute-forcing permutations.
Tools: Amass, altdns, httpx
amass enum -passive -d target.com -o subs.txt
altdns -i subs.txt -o permutations.txt -w ~/bugbounty/wordlists/altdns_words.txt
httpx -l permutations.txt -silent -o live_subs.txt
|
📚 Waybackurls + GF Patterns for Hidden Endpoints
| Extract URLs with vulnerable parameters from archived data.
Tools: waybackurls, gf, uro.
waybackurls target.com > urls.txt
cat urls.txt | gf ssrf | uro > ssrf_urls.txt
cat urls.txt | gf xss | uro > xss_urls.txt
httpx -l ssrf_urls.txt -status-code -title -tech-detect
|
⛏️ Parameter Mining with Arjun
| Discover hidden HTTP parameters.
Tools: Arjun and ParamSpider
arjun -u https://target.com/login -w ~/wordlists/params.txt -o params.json
python3 paramspider.py -d target.com --exclude png,jpg
|
🛢️ Find Live Subdomains
crt.sh/?q=%.target.com | tee crt_subdomains.txt
whois target.com | grep -i "netrange"
nmap -p80,443 -iR 1000 --open -oG open_ports.txt
naabu -list live_subdomains.txt -p 1-65535 -o open_ports.txt
nmap -iL live_subdomains.txt -p- -oN nmap_results.txt
|
📡 Scan for Admin Panels
cat open_ports.txt | httpx -silent -path /admin -path /login -path /dashboard -o possible_admins.txt
|
📤 Open Redirect Testing with gau
gau target.com | grep "redirect" | tee open_redirect_params.txt
|
Keynote
Combining passive sources like archived URLs with active scanning tools such as crawlers, JavaScript analyzers, and fuzzers enables a more complete and efficient discovery of hidden endpoints, sensitive data, and misconfigurations that are often missed in traditional reconnaissance.
Conclusion
By automating and chaining these reconnaissance tools into a unified workflow, security practitioners can drastically reduce manual effort while increasing the depth, speed, and precision of vulnerability discovery across modern web applications.
If you liked my article please leave a respect on my at HackTheBox Profile
